
Ю.А. Семенов (ИТЭФ-МФТИ)
Тотальная зависимость человеческой цивилизации от компьютеров, программ и сетей, делает уязвимыми не только сами технологии, но и человеческую жизнь. К 2025 году базовые технологии передачи и переработки информации выйдут на теоретические пределы, задаваемые физикой, а не технологией! Человечество не смирится с ограничениями, а это означает, что ближайшие 10-15 лет должны быть разработаны принципиально новые технологии для систем памяти, обработки данных и программирования. Причем эти технологии должны базироваться на принципиально иных физических принципах, по сравнению с сегодняшними.
Сорок пять лет назад были заложены основы Интернет, который поменял более чем на порядок одну из важнейших переменных, определяющих темп научно-технического прогресса – задержку с момента возникновения новой идеи или выявления научного факта до ознакомления с этим всех заинтересованных лиц.
Полное число Интернет-объектов сегодня превысило 4 млрд. К 2015 году ожидается, что число подключенных к сети устройств достигнет 15 млрд (по 7 устройств на каждого жителя США).
В 2012 году расходы в сфере ИТ достигнут 1,8 триллиона долларов. Полный объем данных увеличится до 2,7 зеттабайт (+48% по отношению к 2011 году). 90% этих данных неструктурированы (мультимедиа, изображения и WEB).
Ожидается, что стоимость определения генома отдельного человека будет стоить порядка 100$ и это добавит к содержимому медицинской карты еще несколько гигабайт.
К 2020 году память будет стоить 0,5$ за терабайт. В год будет генерироваться в 200 раз больше данных, чем в 2008 году. В 2000 полный трафик Интернет составлял более 1 экзабайта, а в 2010 достиг 256 экзабайт, что соответствует темпу роста в 70 % в год.
Когда Китай и Индия достигнут того же уровня потребления, как и развитые страны, человечеству потребуется 5 планет, таких как Земля (исследование шведских ученых (http://www.scoop.it/t/business-it/p/3341177274/idg-connect-roel-castelein-global-getting-green-it [Getting Green IT])).
Предполагается, что это случится к 2050 году. Чтобы решить возникающие проблемы предлагается широко внедрять планшеты вместо традиционных PC, облачные технологии, рециркуляцию расходуемых материалов и т.д.
Один iPhone 4 в процессе изготовления, транспортировке, использовании и утилизации добавляет в атмосферу 45 кг CO 2
Если совсем недавно объемы данных измерялись мегабайтами и гигабайтами, то теперь речь идет о терабайтах и петабайтах.
Но можно ли утверждать, что количество информации, содержащейся в Гигабайте и в мегабайте логических единиц отличается в 1000 раз?
Возможно, если бы был найден объективный показатель количества информации, проблема присвоения нобелевских премий стала тривиальной.
Количественный рост объемов и потоков данных привел к проблеме нахождения нужной информации в хранилищах и выделения ее в потоках.
Весь окружающий нас мир – это информация, и мы слишком мало о нем знаем. Например, если бы мы всегда знали состав газа во всех наших жилищах, не было бы такого количества сообщений о взрывах домов из-за утечки газа.
| В обиход введен термин «технологии больших объемов данных» (Big data technologies). Это новое поколение технологий и архитектур, разработанных для эффективного извлечения нужной информации из гигантских объемов данных, относящихся к различным типам. |
Big data — это данные, которые превосходят возможности обычных систем баз данных. Чтобы получить то, что нужно, приходится использовать какие-то альтернативные методы обработки.
Для решения этой проблемы (big data) разработана специальная разновидность баз данных NoSQL (http://www.nosql-database.org).
Не следует думать, что большие объемы данных — это то, с чем имеет дело Google или Facebook. На рис. 1. показано распределение объемов данных по областям применения.
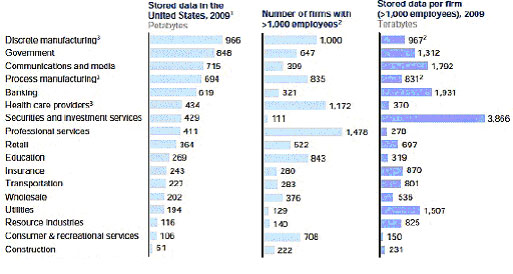
Рис. 1. Распределение объемов данных по областям применения в промышленном секторе
Рассмотрим, что нас ждет в ближайшие 10 лет в сфере информационных технологий.
Нанотехнологии
За последние годы достигнут потрясающий прогресс в информационных технологиях. За 20 лет увеличилось быстродействие вычислительной техники в 1000 раз, пропускная способность каналов возросла в 10000 раз, уже около 30 лет действует закон Мура (удвоение плотности активных элементов на кристалле каждые полтора-два года). Уместно задать вопрос – можно ли ожидать аналогичный темп развития в дальнейшем?
К сожалению, ответ на этот вопрос будет, скорее всего, отрицательным, если ориентироваться на существующие технологии. Используемая технология на кремнии, позволяет работать с разрешением ~15 нм. На подходе мемристоры и графеновые транзисторы (5 нм), но постоянная кристаллической решетки кремния ~ 0,54нм .
Предполагается, что действие закона Мура прекратится к 2020 году (см. рис. 2). 70% поверхности кристалла процессора сегодня занята проводниками, соединяющими активные элементы, что также препятствует росту плотности элементов на кристалле.
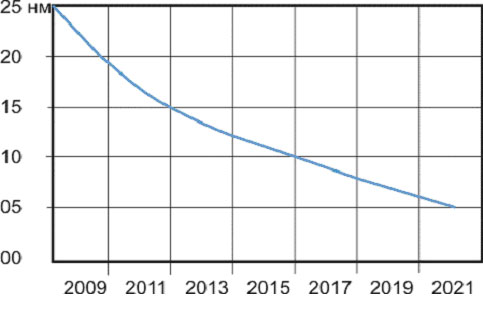
Рис. 2. Экстраполяция закона Мура до 2021 года
Повышение емкостей памяти вызывает миниатюризацию ячеек памяти, а сокращение размера уменьшает заряд, там хранящийся, а это приводит к ухудшению отношения сигнал шум. Неслучайно первый квантовый компьютер работает при температуре 10мК 0 .
Проблемы передачи данных по оптоволоконным каналам
Постоянная поляризации диэлектрика равна 10 -13 сек, а предельная скорость обмена сегодня составляет 10 11 бит/ c . При окне прозрачности кремния ~150нм можно обеспечить до 100 потоков через оптоволокно. Ясно, что возможности прежнего темпа роста скорости передачи данных в ближайшие годы будет исчерпаны.
Около 10 лет назад, когда тактовая частота процессоров приблизилась к 3 ГГц, стало ясно, что дальнейший темп роста тактовой частоты более невозможен. В 2004 году разработчики, чтобы обеспечить рост производительности, перешли на многоядерную архитектуру. Но рост производительности с увеличением числа процессоров имеет логарифмический характер. На теоретический предел мы также выйдем к 2020-25 гг.
Супер-компьютеры
Самая мощная супер-ЭВМ компании Fujitsu (10Пфлоп) в Кобе занимает 800 стоек и потребляет 5 МВт (такую мощность имеет атомная станция в Обнинске). А эта машина на сегодня самая экономная (2,2 Гфлопс/Вт; рис. 3).

Рис. 3. Суперкомпьютер Fujitsu на 10 петафлоп / с
Современный суперкомпьютер может содержать более 100000 узлов. При этом следует иметь в виду, что каждый из них имеет конечную надежность. В 2001 году время наработки на отказ супер-ЭВМ равнялось 5 часам, а в 2012 — 55 часов. Для 100000-узлового компьютера только 35% активности приходится на продуктивную работу. Остальное время занимает формирование точек восстановления ( checkpoint ) и другие вспомогательные операции (см. http://book.itep.ru/depository/super_comp/Supercomputers.mht).
Какими будут суперкомпьютеры следующего поколения? Города стоек, окруженные АЭС, обеспечивающими питание и охлаждение этих машин?
Проблема программных ошибок
Зависимость людей от машин и сетей увеличивается от года к году. От машин зависит сохранность наших средств в банке и даже здоровье. Но программное обеспечение содержит ошибки (после отладки) от 10 до 0,003 на 1000 строк кода. Современное ядро ОС имеют от 50 до 250 млн. строк кода (а еще есть оболочка и приложения). Таким образом, на вашей машине имеется как минимум 1000-20000 программных ошибок. Сегодня ведутся разработки, которые позволят моделировать лекарства, ориентированные на геном конкретного человека. Что будет, если в этой программе будут ошибки ?
В 2000г, программы в автомобиле имели до миллиона строк кодов, к 2010 это число возросло в 100 раз, ожидается, что в 2020 программы в автомобиле будут содержать 10 миллиардов строк кода.
Огромные объемы программ работают на авиалайнерах и других видах транспорта, в медицинских учреждениях, в энергетических системах и т.д. И все эти программы содержат большое число ошибок.
Этот факт ставит перед человечеством проблему создания языков, на которых будет описываться проблема, а не алгоритм ее решения, чтобы минимизировать участие человека в разработке алгоритма. Но для этого нужны системы, обладающие искусственным интеллектом.
Искусственный интеллект
Около 10 лет во многих странах мира активно ведутся работы по созданию систем искусственного интеллекта. Впервые над этой проблемой задумались разработчики безлюдных, автономных видов оружия поля боя. Неоднократно объявлялось, что система, обладающая искусственным интеллектом, создана. Например, система Watson , которая обыгрывает чемпионов в игру типа “ Jeopardy! ” (напоминает “ C вою игру”).
Делаются попытки решить проблему, привлекая технику семантических сетей. Но пока эта проблема не решена. Здесь уместно отослать читателей к книге Роджера Пенроуза “Новый ум короля”, где автор обосновывает невозможность решения проблемы создания искусственного интеллекта на основе модели машины Тьюринга.
Проблемы безопасности
В 2012 году доходы киберпреступников превысили доходы от наркотрафика . Открылась возможность привлечения для хакерских целей высококлассных программистов. Сеть становится все более опасной средой. Учитывая, что в 21-ом веке основным товаром будет информация (описания технологий, программы, сетевые сервисы и пр.), нужны радикальные методы обеспечения сетевой и информационной безопасности. А для всех используемых алгоритмов шифрования пока не доказана теорема криптографической прочности.
Выводы
Тотальная зависимость человеческой цивилизации от компьютеров, программ и сетей, делает уязвимыми не только сами технологии, но и человеческую жизнь.
К 2025 году базовые технологии передачи и переработки информации выйдут на теоретические пределы, задаваемые физикой, а не технологией!
Человечество не смирится с ограничениями, а это означает, что ближайшие 10-15 лет должны быть разработаны принципиально новые технологии для систем памяти, обработки данных и программирования. Причем эти технологии должны базироваться на принципиально иных физических принципах, по сравнению с сегодняшними.